



Anpassung von LLMs für spezifische Anwendungen
Um ein LLM für ein Unternehmen oder einen bestimmten Anwendungsfall zu nutzen, benötigt es oft zusätzliche Informationen über das Unternehmen, eine bestimmte Domäne oder die jeweilige Aufgabe. Abhängig vom Kontext und Anwendungsfall kommen verschiedene Methoden oder Strategien infrage:
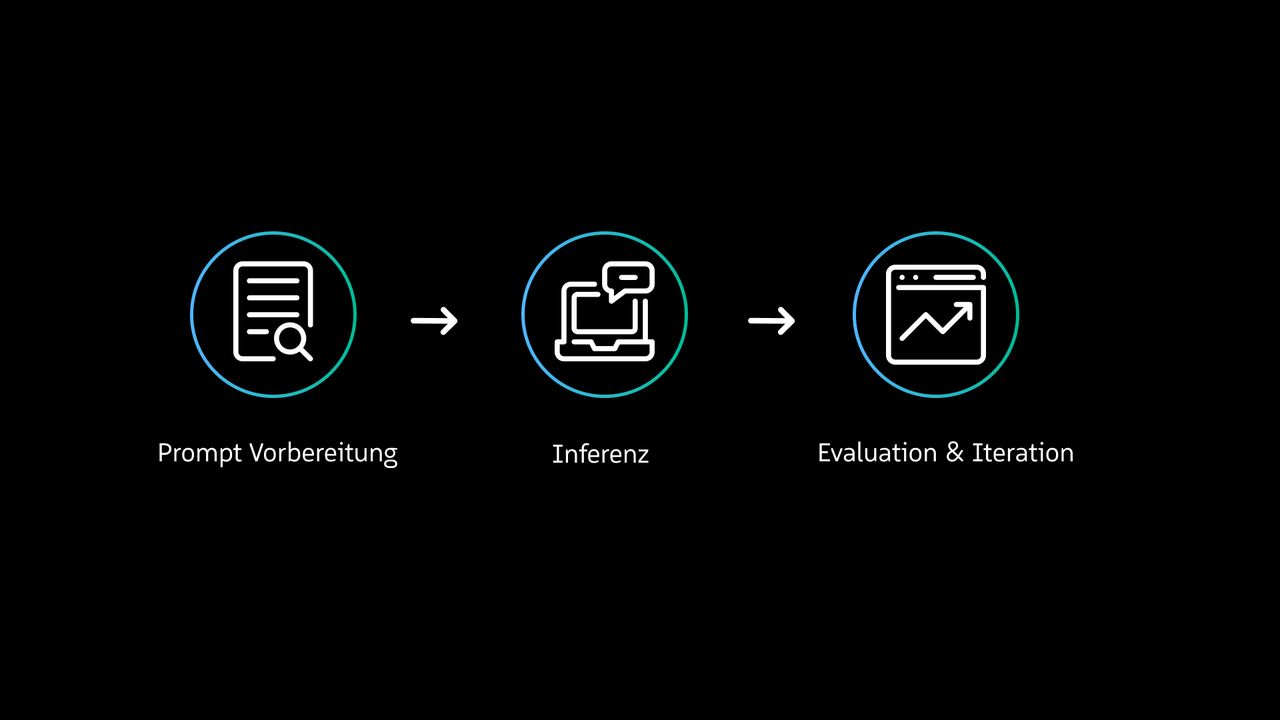
1. In-Context-Learning
Wenn nur wenige Informationen benötigt werden, lassen sich diese direkt bei der Eingabe im Prompt mitgeben. Beim sogenannten In-Context-Learning erlernt das Modell die Aufgabe direkt aus dem Kontext. Zum Beispiel: “Lies dir den folgenden Artikel durch und bestimme die passende Zeitungsrubrik (z. B. Politik, Wirtschaft, Panorama, Sport etc.): Berlin, März 2023 – Mitten im Pazifik entdeckte ein Frachter gestern ein treibendes Wrack. Zwei Überlebende klammerten sich an die Überreste, schwer verletzt, aber am Leben. Die Ursache des Unglücks bleibt unklar …”
Das Modell nutzt den bereitgestellten Input, um ein Muster zu erkennen und eine neue Entscheidung zu treffen, auf der es bisher nicht trainiert wurde. Diese Methode eignet sich zum Beispiel für Text- oder Stiladaptionen für personalisierte E-Mails oder Produktbeschreibungen.
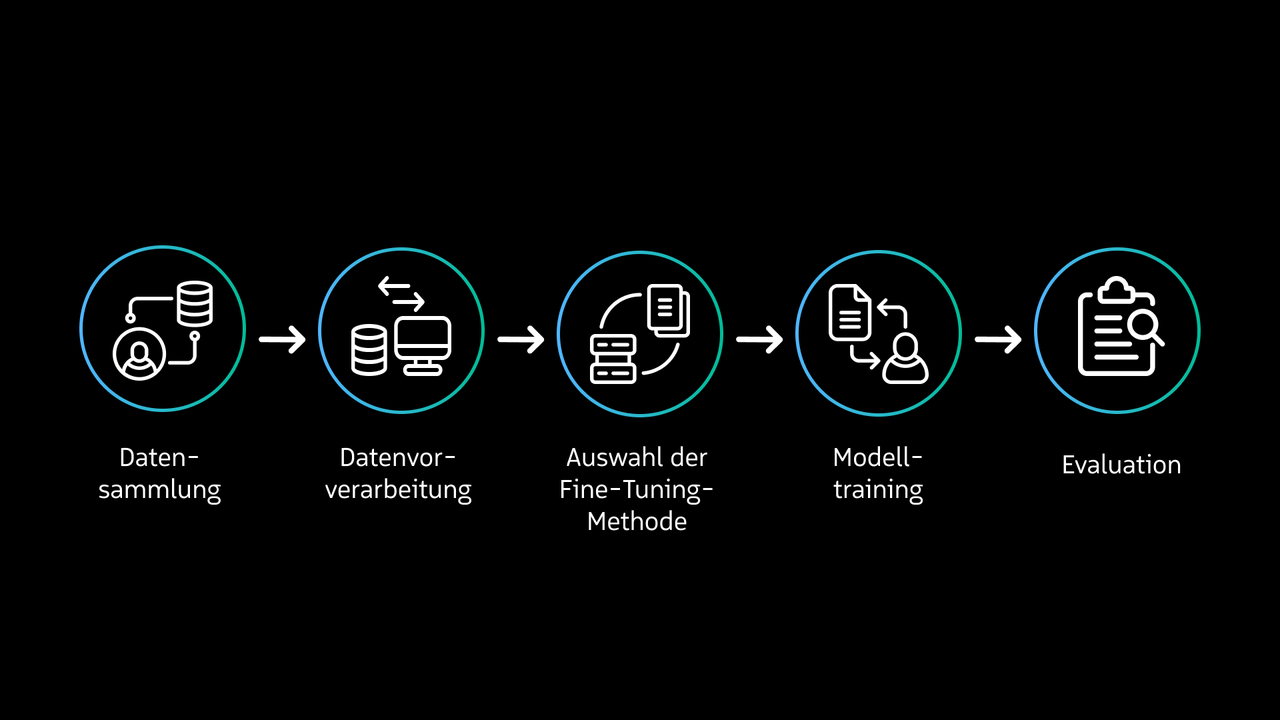
2. Fine-Tuning
Wenn ein Sprachmodell tiefgreifendes Wissen über ein Unternehmen, eine Software oder ein Fachgebiet benötigt, reicht der Platz für den benötigten Kontext im Eingabefeld oft nicht aus. Eine Lösung ist Fine-Tuning. Dabei wird ein bereits trainiertes Modell mit speziellen Daten weiter trainiert. Das Sprachmodell kennt bereits Grammatik und allgemeine Sprachstrukturen, wird aber mit kontextspezifischen Inhalten angereichert. Zwar werden für das Fine-Tuning deutlich weniger Daten benötigt als für das ursprüngliche Training, dennoch braucht es eine angemessene Menge hochqualitativer Daten in einem standardisierten Format. Fehlerhafte Informationen, schlecht dokumentierte Datenbanken oder minderwertige Bild- und Tabellenqualität können das Modell negativ beeinflussen. Ein Nachteil des Fine-Tunings ist, dass bereits integrierte Daten nicht mehr entfernt oder leicht aktualisiert werden können. Fine-Tuning bietet sich beispielsweise für markenspezifische Texterstellung an: Unternehmen trainieren ein Modell auf den eigenen Marketing- und Kommunikationsrichtlinien, um konsistente Inhalte im firmeneigenen Stil zu generieren.
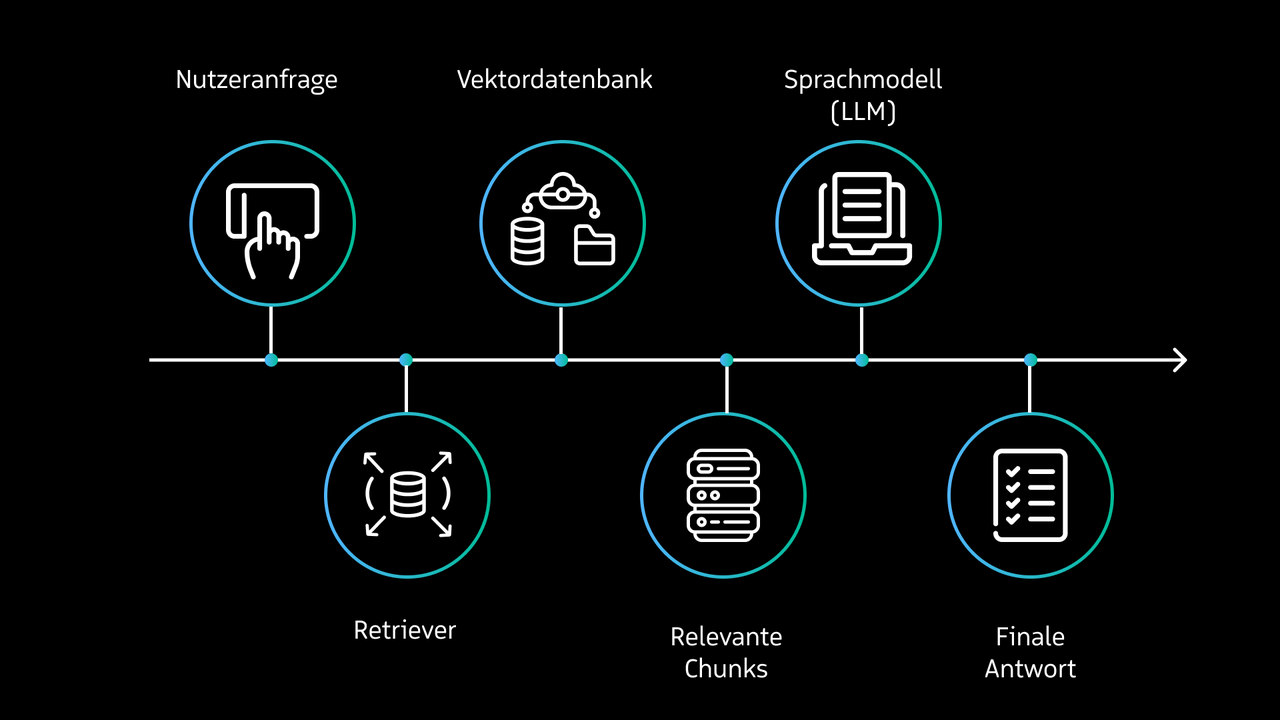
3. Retrieval Augmented Generation (RAG)
Eine besonders effektive Methode zur Bereitstellung relevanter und vor allem faktisch korrekter Informationen ist Retrieval Augmented Generation (RAG). Dabei werden relevante Datenquellen wie Dokumentationen, Workshop-Aufzeichnungen, Erklärvideos oder Anleitungen in einer Vektordatenbank gespeichert und in kleinere Abschnitte (Chunks) unterteilt. Bei einer Nutzeranfrage sucht das System in der Datenbank nach den passendsten Chunks. Diese werden dem Sprachmodell als Kontext im Prompt bereitgestellt, um fundierte Antworten zu generieren.
Vorteile von RAG:
Flexibilität: Datenbanken lassen sich beliebig erweitern und aktualisieren
Präzision: Die Antworten basieren auf spezifischen Informationen
Effizienz: Kein aufwändiges Fine-Tuning des Modells notwendig
Herausforderungen:
Extraktion: Richtige Informations-Chunks finden
Relevanz: Passende Dokumente zur Anfrage selektieren
Semantisches Matching: Kontextuelle Bedeutung korrekt erfassen
Der RAG-Ansatz ist in einer Vielzahl von Anwendungsfällen von Vorteil, z. B. in dynamischen Wissensdatenbanken für Kunden- oder IT-Support oder personalisierte Produktempfehlungen basierend auf Echtzeit-Produktdaten und Nutzerverhalten.
Im AI Exploration Sprint haben wir die RAG-Methodezum Beispiel bei unserem Projekt mit schrempp edv angewandt, um ein Proof-of-Concept zur Integration von KI in die Bestandssoftware zu entwickeln.
)
)
)
)